
Most ebben a bejegyzésben nem mennék bele, hogyan állt elő az az állapot, ami ellen tettem lépéseket, és ennek a cselekvéssorozatnak a tapasztalait, konkrét példáit mutatom meg inkább. Dióhéjban annyi a dolog, hogy van egy családi Synology DS418 NAS 4×4 TB diszk rendszerrel, amin mindent (is) tárolunk, de főleg a fotóinkat. Aztán pár hete szólt egy értesítés keretében, hogy a fotóknak dedikált 2 TB-os mentés nem fér el a Synology C2-es előfizetésben. Gondoltam utána járok, amúgy is már évek óta csak görgetem magam előtt a rendrakást.
Miután végigjártam a NAS1-t, megnéztem a különböző könyvtárakat és lehetőségeket, az alábbi 3 lépéses „akcióterv” (ez a szó mostanában olyan divatos nem?) megvalósítása rajzolódott ki előttem:
- Az összes kép és videó áthelyezése a felhasználó specifikus Synology Photos könyvtárba amiknek normális esetben ott kéne lennie (vannak kivételek).
- Azon fájlok megtalálása és törlése, amik indok nélkül egynél több alkalommal foglalnak helyet (itt is van egy-két kivétel).
- Kis feleségem által (és ez itt nem a vádaskodás helye – Ő így működik) legyártott csilliárd képernyőkép összegyűjtése és válogatása, nem szükségesek törlése.
Az itt leírtak átfutása több napot illetve hetet vett igénybe, mert azért mégis csak egy NAS, a benne rejlő erőforrások nem vethetőek össze egy mai számítógéppel, ráadásul a diszk alrendszer is a tartósság jegyében lett tervezve, nem pedig a sebességére.
Viszont mielőtt még tovább megyek, pár szót a Synology Photos által használt könyvtár struktúráról engedjetek meg, szerintem segíti majd a következő alfejezetekben olvasottak könnyebb megértését.
Fájlokat fogok mozgatni ill. törölni. Legyen mentés mielőtt bármit csinálunk. A leírásból fakadó adatvesztésért semmilyen körülmények között nem vállalok felelősséget, mindenki saját tetteiért és fájljaiért felelős!
Synology Photos
A Synology Photos megköveteli a NAS-on a home szolgáltatást. Linux/Unix-ot használó olvasóknak egyszerű a dolog, szimplán engedélyezi a NAS felhasználók számára a home könyvtárat. A Synology esetében a /volume1/homes/<user> útvonalon van. Windows-t használó olvasók számára ez a szogláltatás lehetővé a teszi a Windows-on ismert C:\Users\<user> könyvtár használatát. Lényegében minden NAS felhasználó kap egy saját könyvtárat, szeparálva a rendszertől.
Az adott felhasználó könyvtárában a Synology Photos létrehoz egy /Photos könyvtárat, ebben fogja felhasználó szinten tárolni a feltöltött fotókat. A feltöltött fotók, a feltöltés módjától függően az alábbi alkönyvtárakban fognak elhelyezkedni:
/MobileBackup– a Synology Photos mobil alkalmazás (Android és Apple által feltöltött képek kerülnek ide)./PhotoLibrary– a böngészőn keresztül feltöltött képek tárolására használt könyvtár.
A /PhotoLibrary-n belül a képeket a rendszer további <év>/<hónap> könyvtárba rendszerezi, tulajdonképpen nincs ez másképp a MobileBackup-nál sem, ott az évet még az eszköz neve (amiről feltöltötték a képet) előzi meg a struktúrában.
Összességében tehát így néz ki a Synology Photos által használt könyvtár struktúra. A könyebb érthetőség miatt a felhasználót is feltüntetem:
/volume1/homes/
├─ thom/
| ├─ Photos/
| | ├─ MobileBackup/
| | | ├─ iPhone/
| | | | ├─ 2022/
| | | | | ├─ 09/
| | ├─ PhotoLibrary/
| | | ├─ 2020/
| | | | ├─ 01/
| | | | ├─ 02/
| | | ├─ 2021/
| | | | ├─ 11/
| | | | ├─ 12/
| | | ├─ 2022/
| | | | ├─ 09/
├─ barbi/
| ├─ Photos/
| | ├─ MobileBackup/
| | | ├─ iPhone/
| | | | ├─ 2022/
| | | | | ├─ 09/
| | | ├─ iPad/
| | | | ├─ 2022/
| | | | | ├─ 06/
| | | | | ├─ 09/
| | ├─ PhotoLibrary/
| | | ├─ 2020/
| | | | ├─ 01/
| | | | ├─ 02/
| | | ├─ 2021/
| | | | ├─ 11/
| | | | ├─ 12/
| | | ├─ 2022/
| | | | ├─ 09/Fotók áthelyezése
Kezdem azokkal, amikkel nem akarok foglalkozni.
Van egy csoportja azoknak a videóknak és képeknek, amiket nem kell majd áthelyezni, mert valamilyen oknál fogva nem oda tartoznak. Ilyenek például a projekt videók/képek, Final Cut Pro-ban használt nyersek, szkennelt dokumentumok /Documents stb. Ezeket a fájlokat jól tudom azonosítani, mert valamilyen felsőbb rendű könyvtárban foglalnak helyet (/Work, /FCPBackups stb.). Nem akarok továbbá foglalkozni a 0 byte méretű fájlokkal valamint üres könyvtárakkal. Szintén nem kell foglalkozni a Synology meta fájlokkal és könyvtárakkal, ezek .@eaDir nevű rejtett könyvtárban vannak.
A többi megtalálásához viszont a find parancsot fogom használni (Linux/Unix felhasználók megint csak helló!), viszont ehhez be kell lépni a NAS-ra SSH2-n keresztül. A DSM (Synology NAS operációs rendszere) 7-es verziója ezen egy kicsit már nehezített (pontosabban szigorúbb lett), így ennek megértéséhez és elvégzéséhez a gyártó ide vonatkozó oldalát javaslom itt.
No, miután bejutottunk a NAS-ra, egy nagyon kövér, ám de jól irányzott find paranccsal máris munkára foghatjuk a NAS-t. A keresést a /homes könyvtárból indítom, hiszen minden felhasználó neve alatt keresni kívánok (lásd fenti struktúra ha nem érthető):
find . -type f ! -size 0 \
! -path '*/admin/*' ! -path '*/*@eaDir/*' \
! -path '*/Documents/*' ! -path '*/Work/*' \
! -path '*/FCPBackups/*' ! -path '/Photos/*' \
\( \
-iname "*.png" -o -iname "*.jpg" -o -iname "*.jpeg" -o \
-iname "*.bmp" -o -iname "*.gif" -o -iname "*.heic" -o \
-iname "*.mov" -o -iname "*.avi" -o -iname "*.mp4" -o -iname "*.m4v" \) > files.txtBontsuk darabjaira a fenti parancsot mert valóban nem rövid, ám annál egyszerűbb:
find .keresés indítása a jelenlegi könyvtárból indulva (írtam, ez a/homeskönyvtár esetemben).-type fcsak fájlokra vagyok kiváncsi, könyvtárakra nem. Tehát például egyIMG_0001.JPGnevű könyvtár nem kerül bele a listába.! -size 0csak a 0 byte-nál nagyobb méretű fájlok kellenek. (A!jel a tagadást jelenti itt is és a többi paraméternél is; tehát a jelentése „minden, ami nem 0 byte méretű”.)! -path '*/admin/*'hagyd figyelmen kívül azokat a fájlokat, amelyeknek az útvonalában benne van a megadott útvonal részlet. Pl.: a/thom/cms/admin/reload.gifkimarad, mert benne van az/admin/.-iname "*.png"csak a felsorolt kiterjesztésű fájlokra vagyok kiváncsi. Azért-inameés nem csak-name, mert így a kis- és nagybetű közti különbség nem fog számítani (imintinsensitive), úgyanúgy érdekelt vagyok azimage001.pngképben mint azimage001.PNG-ben.> files.txta találati listát afiles.txtnevű fájlba tegye bele a jelenlegi könyvtárban, ne a képernyőre írja ki.
Ez a parancs a fájlok mennyiségétől ill. a könyvtárstruktúra komplexitiásától függően egy darabig el fog tartani.
Amikor elkészült, akkor a keletkezett fájlban ilyen bejegyzések lesznek (már ha volt találat):
./Drive/GoogleDriveBackup/Google Fényképek/2015/10/IMG_0012.JPG
./Drive/GoogleDriveBackup/Google Fényképek/2015/10/IMG_2982.JPG
./Drive/GoogleDriveBackup/Google Fényképek/2015/10/IMG_3134.JPG
./Drive/GoogleDriveBackup/Google Fényképek/2015/10/IMG_0030.JPG
./Drive/GoogleDriveBackup/Google Fényképek/2015/10/IMG_2939.JPG
./Drive/GoogleDriveBackup/Google Fényképek/2015/10/IMG_3072.JPG
./Drive/GoogleDriveBackup/Google Fényképek/2015/10/IMG_2955.JPG
./Drive/GoogleDriveBackup/Google Fényképek/2015/10/IMG_3035.PNG
./Drive/GoogleDriveBackup/Google Fényképek/2015/10/IMG_2886.JPG
./Drive/GoogleDriveBackup/Google Fényképek/2015/10/IMG_3143.JPG
./Drive/GoogleDriveBackup/Google Fényképek/2015/10/IMG_3006.JPGÉn az alábbi dolgokat tettem attól függően, hogy mit tudtam a fájlról:
- Ha egyértelmű volt, hogy mikor készült (mint a fenti példában), akkor NAS szinten átmozgattam a megfelelő
/MobileBackupalatti könyvárba. Hogy elkerüljem a fájlnév általi ütközést, így amvparancsnak megadtam a--backup=numberedkapcsolót és ha ütközés van, akkor hozzáilleszti a~N~-t a kiterjesztés végéhez, aholNegy növekvő szám attól függően, hányszor volt ütközés. Később még írok ezen fájlok további feldolgozásáról. Például:
IMG_001.png
IMG_001.png.~1~
IMG_001.png.~2~ - Ha nem, akkor pedig letöltöttem a gépemre, majd a weben újra feltöltöttem őket. Így a Synology Photos képfeldolgozó logikájára bíztam a dolgot ami két dolgot jelentett:
- Szépen feldolgozta az EXIF és egyéb adatok alapján a képet és jó helyre pakolta.
- Mivel nekem a Synology Photos úgy van beállítva, hogy a duplikált fájlokat feltöltés után figyelmen kívül hagyja, így legalább egy adag duplikált fájltól megszabadulok (ha már eleve volt egy példány belőle a Synology Photos könyvtárában – és volt sok ilyen képem).
Ezzel az első lépcsővel meg is vagyunk.
Többszörösen tárolt fájlok felkutatása és törlése
Mivel én végigjártam a Synology Photos – Moments – Synology Photos evolúciót, akadtak olyan könyvtárak és fájlok, amiket nyugodt szívvel törölhettem. Ilyenek voltak az üres könyvtárak, már érvényét vesztett @eaDir könyvtárak stb., így kezdésnek toltam egy törlést ezekre a fájlokra ill. könyvtárakra, szintén a find paranccsal.
Érvényét vesztett @eaDir könyvtárak törléséhez ezt:
find . -type d -name "@eaDir" -print -exec rm -rf \;A parancs lényege, hogy csak könyvtárakat keres (-type d; d mint directory) és csak olyat, amiknek a nevében bene van a @eaDir. A -print kiiratja a kimenetre ha van talált és az -exec rm -rf pedig törli a talált könyvtárat.
Az üres könyvtárak törléséhez pedig ezt a parancsot használtam:
find . -size 0 -print -deleteMost jön a neheze és a legidőigényesebb rész, a többszörös fájlok felkutatása. Ugye most, hogy minden képet és videót bemozgattunk az adott felhasználó /Photos könyvtárába, így nyugodtan dolgozhatunk ezen a szinten, így legalább nem fogjuk feldolgoztatni azokat a fájlokat a NAS-sal, amik nem relevánsak.
Azt is fontos megjegyeznem, hogy itt szigorúan a bitre azonos fájlokat fogom megkeresni a felbontásból vagy egyéb szempontból eltérő képeket nem (pl.: ugyanabból a képből van
JPGésNEFváltozat is).
A módszer a következő: minden fájlból generáltatok egy MD5 lenyomatot, amit listába szervezek. Utána lehet majd tovább feldolgozni. A parancs következő:
find . ! -path '*/@eaDir/*' -type f -exec md5sum {} + | sort | uniq -w32 -dD > duplicates.txtEzt is kifejtem részletesen:
find .keresés indítása a jelenlegi könyvtárból indulva (írtam, ez a felhasználó/Photoskönyvtára).! -path '*/@eaDir/*'bármilyen esetben figyelmen kívül akarom hagyni a@eaDirkönyvtárat.-type fcsak fájlok érdekelnek, könyvtárak nem (-fmintfiles).-exec md5sum {} +a megtalált fájlokból egy MD5 lenyomtatot képzünk, a+jel segítségével pedig az összes fájlt azmd5sumparancs bemenetére füzzük. Így egyszer fogja a rendszer lefuttatni (md5sum file1 file2 fileN) ahelyett, hogy minden egyes fájlra külön-külön meghívnánk (md5sum file1, aztánmd5sum file2stb.).| sorta|(pipe) karakter az előtte lévő parancs eredményét irányítja asortparancs bemenetére, ezzel ABC sorrendbe rendezzük a találatokat, ebben az esetben már az MD5 lenyomatokat.| uniq -w32 -dDszintén egy pipe karakter, majd auniqparancs segítségével összerendezem az egyező MD5 lenyomatokat. A-w32arra utasítja auniqműködését, hogy csak az első 32 karaktert vizsgálja (ilyen hosszú amúgy az MD5 érték), a-dDpedig az összes duplikátumot listázza, akkor is ha ismétlődik.> duplicates.txta találati listát aduplicates.txtnevű fájlba tegye bele a jelenlegi könyvtárban, ne a képernyőre írja ki.
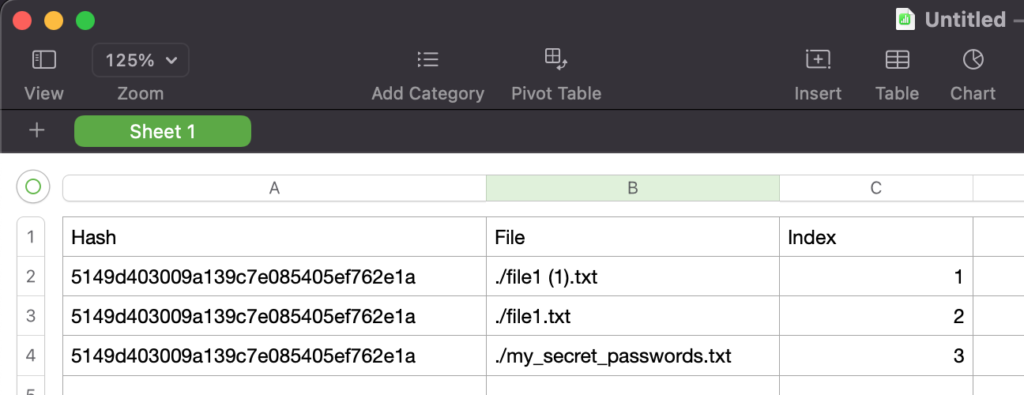
A példa kedvéért egy egyszerű minta. A következő 5 fájlom van:
file1.txtfile1 (1).txtabc.txtdef.txtmy_secret_passwords.txt
A file1.txt, file1 (1).txt és my_secret_passwords.txt pontosan ugyanaz a fájl, az abc.txt és a def.txt pedig eltérőek. A fenti parancs kiadása után az alábbi eredmény fog keletkezni:
cat duplicates.txt
5149d403009a139c7e085405ef762e1a ./file1 (1).txt
5149d403009a139c7e085405ef762e1a ./file1.txt
5149d403009a139c7e085405ef762e1a ./my_secret_passwords.txtLátható, hogy a teljesen egyedi fájlok be sem kerültek a listába (hiszen egy darab másolatuk sincs), viszont a másik háromból mindhárom. Mindhárom fájl MD5 lenyomata 5149d403009a139c7e085405ef762e1a ami pontosan 32 karakter (-w32), csak ezt kell vizsgálni, illetve a -dD miatt mindegyik példány megjelenik.
Ezt az elkészült listát tovább alakítottam. Első lépésként a sed paranccsal lecseréltem az MD5 érték és a fájl neve közötti szóközöket vesszőre. A fenti példa fájlon bemutatva, a parancs illetve a módosítás eredménye:
sed -i "s/ /,/g" duplicates.txt
cat duplicates.txt
5149d403009a139c7e085405ef762e1a,./file1 (1).txt
5149d403009a139c7e085405ef762e1a,./file1.txt
5149d403009a139c7e085405ef762e1a,./my_secret_passwords.txtLátható, hogy a dupla szóközt cseréltem vesszőre. Ez könnyíti a Numbers importot. Következőnek letöltöttem a gépre az átalakított fájlt és egy Numbers-be (Excel for Mac) beimportáltam. Egy egyszerű COUNTIF művelettel csináltam egy index oszlopot.
COUNTIF(A$1:A3;A)Végezetül, egy szűrővel minden olyan hagytam csak megjelenni, ahol ez az index nagyobb volt mint 1.
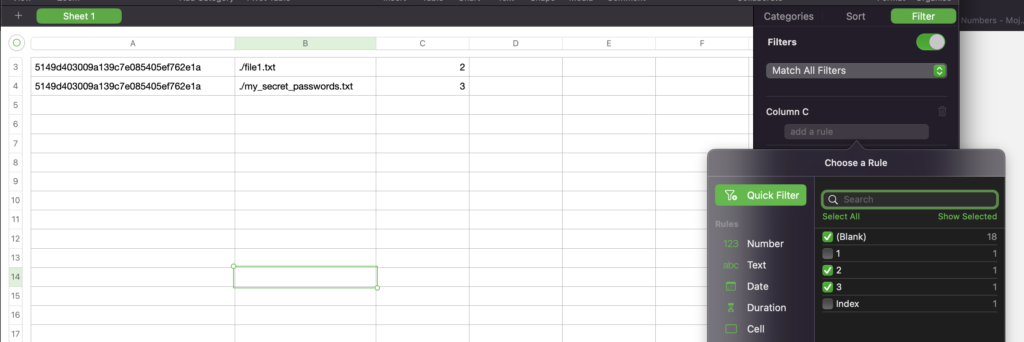
A megmaradt soroknál kijelöltem a fájlnevet tartalmazó oszlopot és egy szövegszerkesztővel törlési parancsokra alakítottam azokat.
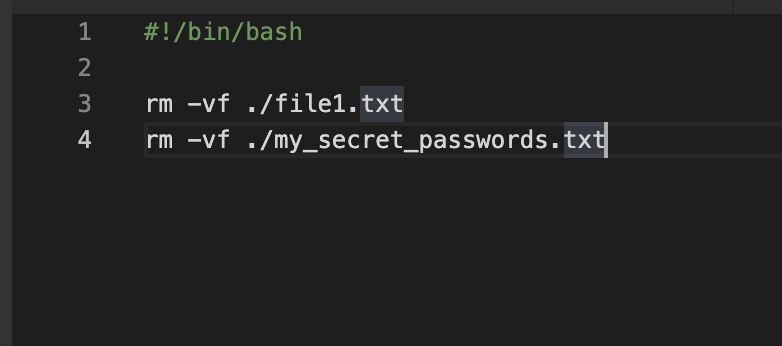
Az elkészült listát egy futtatható script-ként visszamásoltam a NAS-ra és lefuttatásával letöröltem azokat.
./delete_dups.sh
removed './file1.txt'
removed './my_secret_passwords.txt'Ez volt szerintem a nehezebbik.
Képernyőfotók azonosítása és konszolidálása
Ahogy már említettem, feleségem szeret képernyőképekkel dokumentálni. Viszont ezek a képek nagy része időszakos, hamar érvényét vesztik, ám a törlés sokszor elmarad.
Mivel mi csak Apple készülékeket használunk, így arra gondoltam, hogy az ismert készülékek kijelző felbontásából kiindulva fogom kiválogatni a készülékeket (portré és fekvő mód egyaránt).
Szóval első lépésként összegyűjtöttem az összes korábban és jelenleg használt iPhone (és iPad) modellek portré ill. fekvő módban lévő felbontását. Igazából a lista ugyanaz, csak a szélességi és magassági pixel értékek vannak felcserélve.
| iPhone portré | iPhone fekvő mód | iPad portré | iPad fekvő mód |
| 1170×2532 | 2532×1170 | 1488×2266 | 2266×1488 |
| 1080×2340 | 2340×1080 | 1620×2160 | 2160×1620 |
| 1284×2778 | 2778×1284 | 2048×2732 | 2732×2048 |
| 750×1334 | 1334×750 | 1668×2388 | 2388×1668 |
| 1242×2688 | 2688×1242 | 1640×2360 | 2360×1640 |
| 1125×2436 | 2436×1125 | 1536×2048 | 2048×1536 |
| 828×1792 | 1792×828 | 1668×2224 | 2224×1668 |
| 1080×1920 | 1920×1080 | 768×1024 | 1024×768 |
| 1242×2208 | 2208×1242 | ||
| 640×1136 | 1136×640 | ||
| 640×960 | 960×640 | ||
| 320×480 | 480×320 |
Ezeket az értékeket felhasználva egy újabb jól irányzott find parancs építhető, de mielőtt még megtenném, a /Photos könyvtár alatt minden felhasználónál létrehoztam egy /Screenshots könyvtárat. Erre azért van szükség, mert a korábban ismertetett módszerrel (duplikátumok törlése) ebbe a könyvtárba fogom mozgatni a képeket egy utolsó áttekintési lehetőséget biztosítva. Mivel az iPad felbontások között van egy-két nagyon standard (1024×768 például), így szeretnék meggyőződni arról, hogy csak olyan képek kerülnek majd törlése, amiket valóban kell és mondjuk nem egy 2000-es évek elején készült 1 megapixeles HP géppel készült fényképről van szó (amikor ez a felbontás volt az elérhető méret).
A felbontási adatokkal tehát az alábbi find parancs állt össze:
find ~+ -type f ! -path "*eaDir*" \( -iname "*.png" -o -iname "*.jpg" \) \
-exec bash -c 'identify -format "%d/%f %wx%h\n" "{}" | grep \ "2266x1488\|2160x1620\|2732x2048\|2388x1668\|2360x1640\|2048x1536\|2224x1668\|1024x768\|1488x2266\|1620x2160\|2048x2732\|1668x2388\|1640x2360\|1536x2048\|1668x2224\|768x1024\|2532x1170\|2340x1080\|2778x1284\|1334x750\|2688x1242\|2436x1125\|1792x828\|1920x1080\|2208x1242\|1136x640\|960x640\|480x320\|1170x2532\|1080x2340\|1284x2778\|750x1334\|1242x2688\|1125x2436\|828x1792\|1080x1920\|1242x2208\|640x1136\|640x960\|320x480"' \; \
> screenshots.txtRészleteiben nézzük meg ezt is:
find ~+keresés indítása a jelenlegi könyvtárból indulva (ezt is a felhasználó/Photoskönyvtárából). A~jel annyi könnyebbséget ad, hogy a fájlok útvonalához hozzáteszi a teljes útvonalat ahol megtalálta, így később könnyebb lesz majd mozgató parancsot kreálni a listából.-type fcsak fájlok érdekelnek, könyvtárak nem (-fmintfiles).! -path '*/@eaDir/*'bármilyen esetben figyelmen kívül akarom hagyni a@eaDirkönyvtárat.( -iname "*.png" -o -iname "*.jpg" )csak a felsorolt kiterjesztésű fájlokra vagyok kiváncsi. Azért-inameés nem csak-name, mert így a kis- és nagybetű közti különbség nem fog számítani (imintinsensitive), úgyanúgy érdekelt vagyok azimage001.pngképben mint azimage001.PNG-ben.-exec bash -c '' \;az ez után megadott parancsotbashscript-ként kell majd futtatni.identify -format "%d/%f %wx%h\n" {}afindparancs által megtalált fájlon hívja meg azidentifyparancsot egy egyedi kimenet formátummal, ahol csak a könyvtár és a fájl neve (%d/%f) ill. a kép felbontása (%wx%h) fog megjelenni*.| grep "2266x1488 [...] 320x480" \;újabb pipe, majd agrepparanccsal csak akkor engedjük tovább a kapott értéket, ha felsorolt felbontás kombinációk egyike igaz lesz. A felbontás értékek szintén pipe karakterrel vannak elválasztva mert reguláris kifejezésként van használva a lista, azonban a bash környezeti karaktervédelmekről és specialitásokról most nem szól a leírás.> screenshots.txta találati listát ascreenshots.txtnevű fájlba tegye bele a jelenlegi könyvtárban, ne a képernyőre írja ki.
*: Köszi connor-nak az építő kritikát, így egy fokkal még egyszerűbb lett a dolog.
Egy gyors példa az identify és grep kombinációra. Adott a következő kép: screenshot_01.png, amit a find parancs felfedezett. Az identify parancs alapértelmezetten a következő információt adja vissza a képről:
find ~+ -type f -exec bash -c 'identify -format "%d/%f %wx%h\n" "{}"' \;
/volume1/homes/user/Photos/MobileBackup/iPhone/2022/01/screenshot_01.png 1170x2532Végezetül a pont az i-n, a grep:
find ~+ -type f -exec bash -c 'identify -format "%d/%f %wx%h\n" "{}" | grep "2266x1488\|2160x1620\|2732x2048\|2388x1668\|2360x1640\|2048x1536\|2224x1668\|1024x768\|1488x2266\|1620x2160\|2048x2732\|1668x2388\|1640x2360\|1536x2048\|1668x2224\|768x1024\|2532x1170\|2340x1080\|2778x1284\|1334x750\|2688x1242\|2436x1125\|1792x828\|1920x1080\|2208x1242\|1136x640\|960x640\|480x320\|1170x2532\|1080x2340\|1284x2778\|750x1334\|1242x2688\|1125x2436\|828x1792\|1080x1920\|1242x2208\|640x1136\|640x960\|320x480"' \;
/volume1/homes/user/Photos/MobileBackup/iPhone/2022/01/screenshot_01.png 1170x253Remélem így érthető. Most, hogy előlállt a feltételezett képernyőképek listája a screenshots.txt fájlban, innen már nem nagy művészet egy kis Excel / Numbers / sed segítségével egy olyan bash script-et csinálni, ami bemozgatja ezeket a fájlokat a megfelelő /Screenshots könyvtárba. Erre már nem térek ki, mint ahogy utána a Synology Photos-ban történő „szemmel verés” esetére sem. 😉 Egy kis súgó, de nem bontom ki!
sed -E 's@^(.*)/(.*)\ (.*)$@mv -vf --backup=numbered \1/\2 /volume1/homes/user/Photos/Screenshots/\2@gm' screenshots.txt > mv_screenshots.txtAz előző parancs hatására ebből:
/volume1/homes/user/Photos/MobileBackup/iPhone/2022/01/screenshot_01.png 1170x2532
/volume1/homes/user/Photos/MobileBackup/iPhone/2022/01/fontos_akcio.png 1170x2532
/volume1/homes/user/Photos/MobileBackup/iPhone/2022/01/IMG_0004 (2).png 2360x1640Ez lett:
mv -vf --backup=numbered \
/volume1/homes/user/Photos/MobileBackup/iPhone/2022/01/screenshot_01.png \
/volume1/homes/user/Photos/Screenshots/screenshot_01.png
mv -vf --backup=numbered \
/volume1/homes/user/Photos/MobileBackup/iPhone/2022/01/fontos_akcio.jpg \
/volume1/homes/user/Photos/Screenshots/fontos_akcio.jpg
mv -vf --backup=numbered \
/volume1/homes/user/Photos/MobileBackup/iPhone/2022/01/IMG_0004 (2).png \
/volume1/homes/user/Photos/Screenshots/IMG_0004 (2).png Amivel viszont adós vagyok, az az index suffix-szel (~N~) rendelkező fájlok kezelése. Lássuk hát…
Sorszámozott fájlok kezelése
Ahogy korábban írtam, a mv parancsnak van egy olyan kapcsolója, amivel név ütközés esetén egy növekvő számmal szuffixeli a mozgatott fájlt. A probléma az, hogy a parancs ezt a szuffixet a kiterjesztés után fűzi a fájl nevéhez hozzá, így a Synology Photos számára nem lesz látható. Végtére is, a valami.png.~1~ vagy a kiskutya.jpg.~12~ nem igazán érvényes kép kiterjesztések. Persze elvárhatnánk tőle, hogy bele is nézzen és a MIME típus alapján eldöntse, valljuk be: több százezer képnél ez eléggé időigényes volna.
Szóval két lépésre van szükség:
- Egy jól kialakított
findparanccsal megkeressük ezeket a fájlokat. Szerintem ez már mindenkinek menne, annyitfind-oztunk ebben a bejegyzésben. - Az elkészült fájllistát át kell alakítani egy újabb
mvparancs listára, hogy átnevezzük a fájlokat.
Tehát, a fájlok megtalálásához az alábbi parancsra van szükségünk:
find . -type f -name "*~" > numbered.txtEgész rövid az eddigiekhez képest. A lényeg:
find .keresés indítása a jelenlegi könyvtárból indulva (ezt is a felhasználó/Photoskönyvtárából).-type fcsak fájlok érdekelnek, könyvtárak nem (-fmintfiles).-name "*~"csak azokra a fájlokra van szükség, amik~végződnek.
A keletkezett listát pedig az alábbi sed paranccsal tudjuk használható formára hozni:
sed -E 's@^(.)/(.)(\..*)(\..*)$@mv -vf --backup=numbered \0 \1/\2\4\3@gm' numbered.txt > mv_numbered.txtÖsszegzés
270 GB. KETTŐSZÁZHETVEN! Ennyi helyet nyertem ezzel az akcióval. Magáért beszél. Nem számítottam rá de tényleg szép eredmény szerintem. Más kérdés, hogy ki kell várni az időt, mie a Synology Photos újra indexeli a könyvtárakat, ez nálam hetek volt. Nem vicc, hetek!
Ami a leírást illeti: sokat tanultam a feladatból. Nem volt számomra ismeretlen a környezet, de a find, mv és a sed paracsoknál sokat tanultam. Regexp-ből sem vagyok feketeöves, de azért boldogulok vele, szóval ha valahol lehetne egyszerűsíteni és tudod is hogyan, bátran oszd meg velem, nyitott vagyok rá.
Végezetül, ha a duplikált fájlos résznél a Numbers-t ki tudnám hagyni a sorból és tisztán megoldani a NAS-on, nagyon boldog lennék, de ez már csak amolyan szakmai kiváncsiság, még keresem.
Legyen mentés! Nem vicc! Gyorsan rosszra lehet fordítani a dolgokat egy félresikrült rm -vf-fel vagy mv-val.
Végezetül: remélem hasznos volt!
——————————————————————————————
- 1 NAS: Network Attached Storage
- 2 SSH: Secure Shell
Photo by Alex Cheung on Unsplash



